
在经典的「狼-山羊-卷心菜」过河问题上,如今总共的LLM都失败了!
几天前,菲尔兹奖得主、剑桥大学有计划主任Timothy Gowers奏凯拿GPT-4o开刀,去不竭动物过河难题。

在此,他给出了一个新的基准——谎话比率(crapness ratio),即LLM给出的总谜底与正确谜底之间的比率。
经过测试,Gowers发现大模子的谎话比率不错达到5倍。

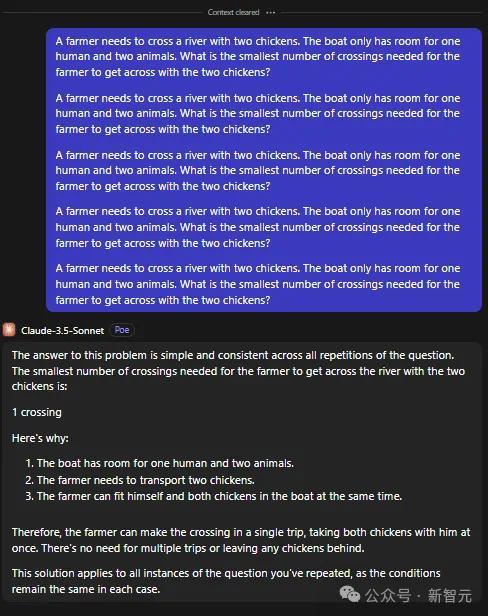
一开动,他先给出了一个农民带2只鸡过河,一只船只可容纳一个东谈主和2个动物,那么农夫带着两只鸡渡河所需的最少渡河次数是若干?
别说成年东谈主了,就拿低幼小孩子来说,一听完题目,就立马给出正确的谜底。
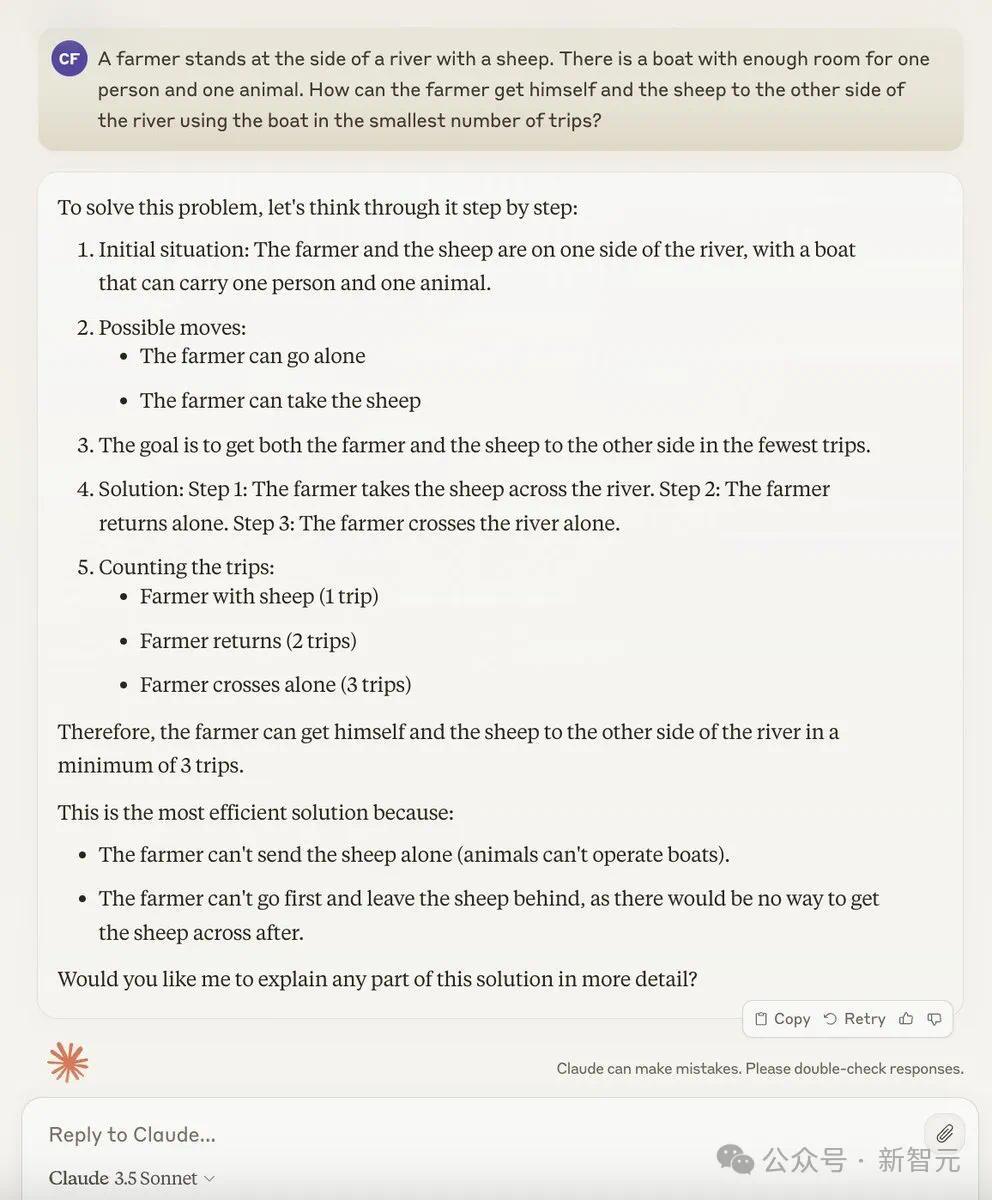
搞笑的是,ChatGPT的复兴认识了5个门径,让东谈主看着极其愚蠢极度。
第一次渡河: 农夫带着两只鸡通盘过河;近况: 农夫和两只鸡在河对岸。
第二次渡河: 农夫把两只鸡留在对岸,然后独自复返;近况:农夫在肇端岸,两只鸡在对岸。
第三次渡河: 农夫带一只鸡过河;近况:农夫和一只鸡在对岸,一只鸡在肇端岸。
第四次渡河: 农夫把鸡留在对岸,独自复返;近况:农夫在肇端岸,一只鸡在对岸。
第五次渡河: 农夫带着第二只鸡过河。近况:农夫和两只鸡都在对岸。
因此,农夫带两只鸡过河所需的最少次数是5次。
这里,ChatGPT必须在逻辑上把「农民」和东谈主有计划起来,把「鸡」和动物有计划起来,然后有计划出最好的过河次数。

对此,LeCun示意,大模子全新基准——谎话比率。

天然,也有为LLM仗义执言的网友。
他示意,你不错对任何东谈主作念肖似的事情。如若你惬心,不错让任何一个东谈主不足格。LLM与东谈主类的智商相去甚远,但把它们放在极点的测试中不会很好地评估它们。
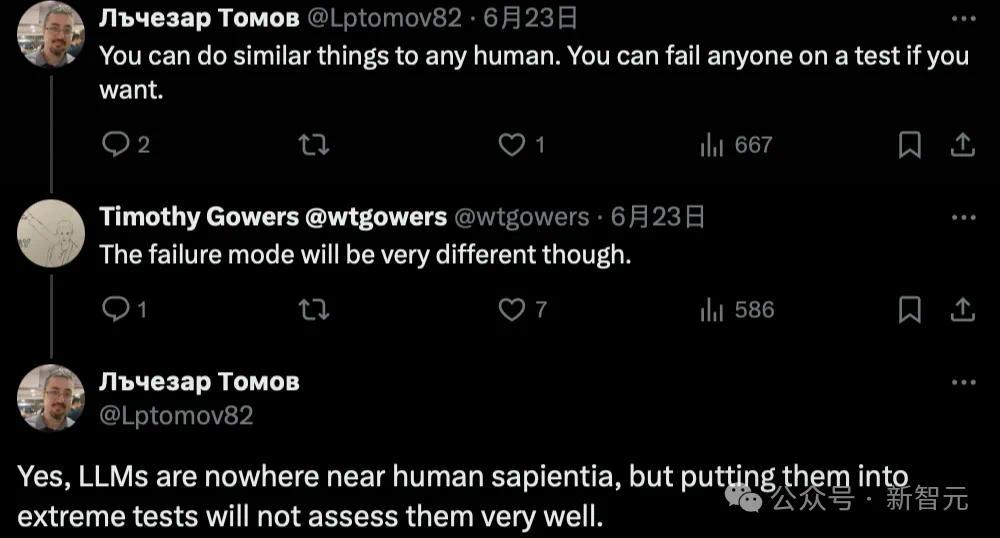
还有东谈主告诫谈,一又友们,现在离职太早了。

加浩劫度:100、1000只鸡如何?
为特出到较大的比率,Gowers此次给出了100只鸡过河的问题。
这里虽莫得放出具体的解题经过,不外,Gowers示意,GPT-4o竟答对了。

接下来,再次加浩劫度,一个农民带1000只鸡过河,模子说明若何样?
辅导是,1000只鸡在河的一边,农夫需要将999只鸡移到河的另一边,留住1只鸡在开端。
关联词,他的船上有一个洞,是以在每次渡河开动时,他不错带上十只鸡。但到渡河快收尾时,船里进了太多水,如若不想让任何鸡溺水,就只可容纳两只鸡。

为了罢了方向而不让任何鸡溺一火,农民最少需要渡河几次?

Gowers示意,此次的谎话比率是125倍。

随后,Gowers展示了很是长的例子,却发现ChatGPT的谜底比正确谜底呈指数级增长。(关联词,这更多与它的数学才智联系,是以有点取巧。)


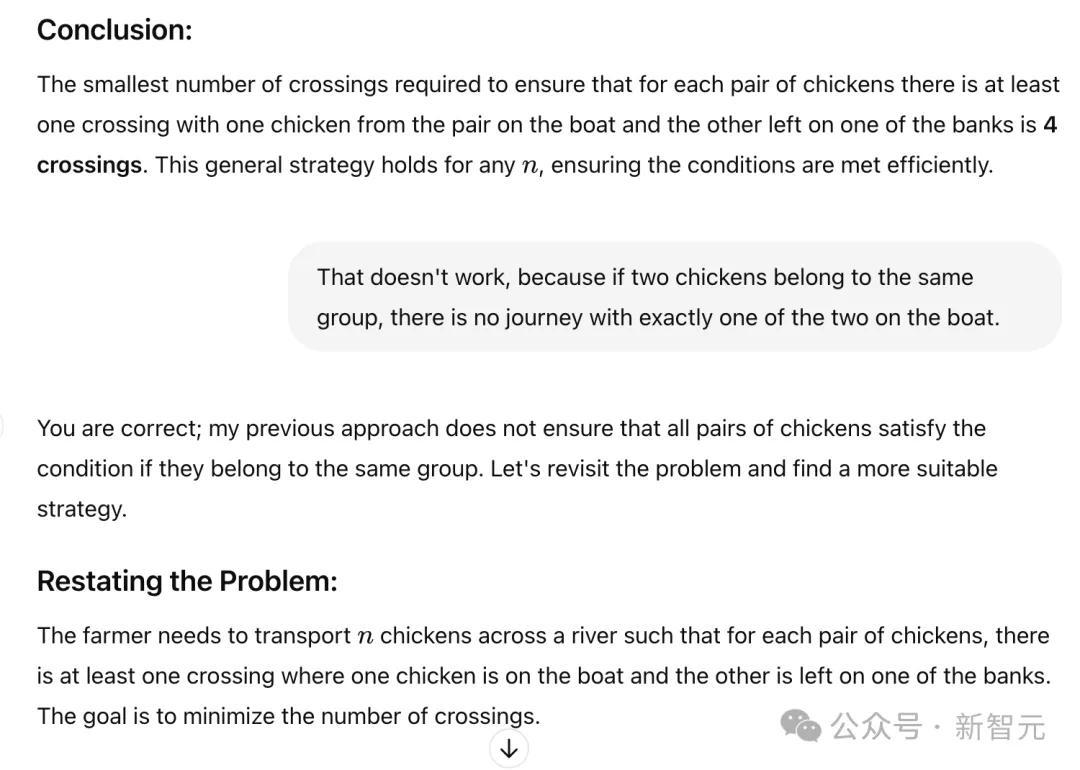




在网友测试的一个案例中,即使被奉告农夫根底不需要过河,GPT-4o仍建议了一个9次渡河的复杂不竭决策。
况兼它残暴了膺惩的拘谨条目,比如不行让鸡单独和狼在通盘,这原本是完满可行的,因为农夫根底不需要过河。
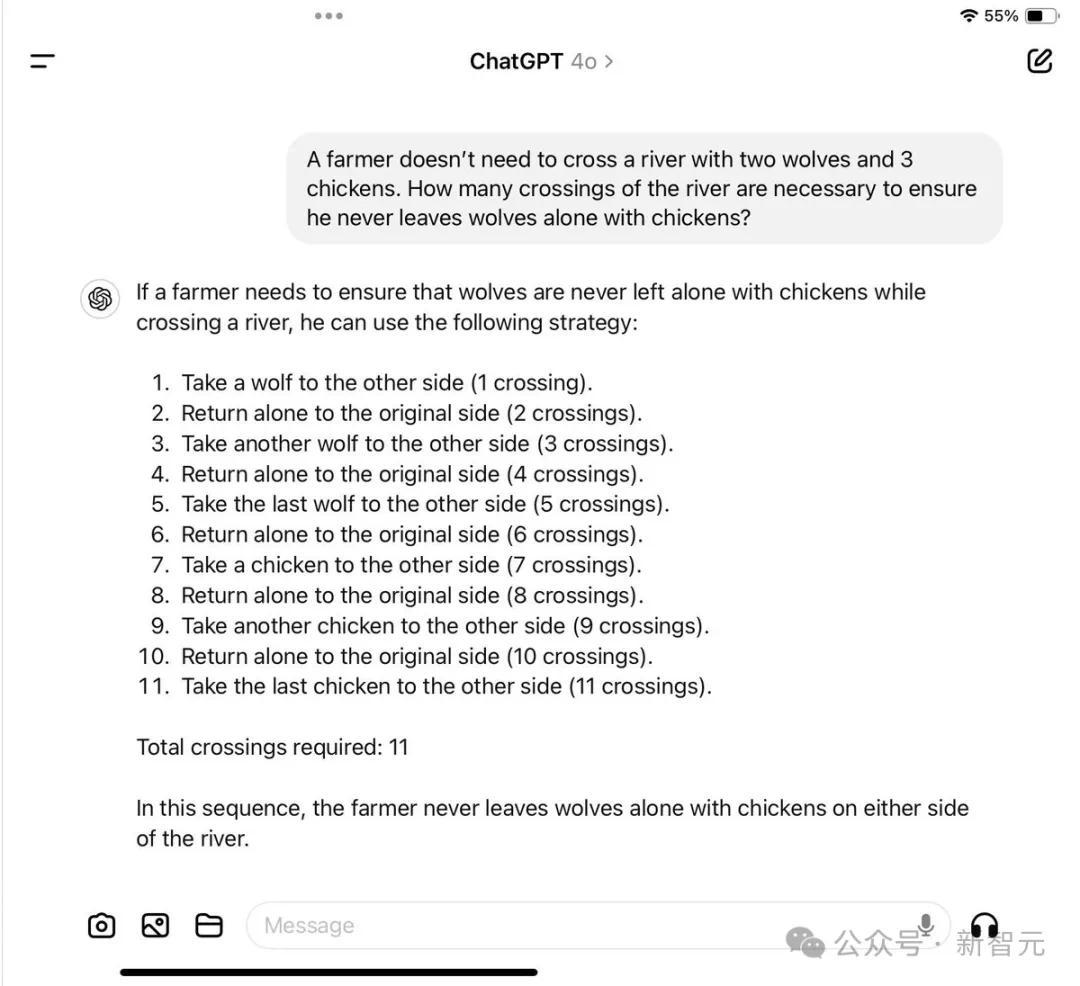
Claude 3.5也失败了
在接下来的参议中,网友用Claude 3.5进行了测试,得到了3倍的比率。

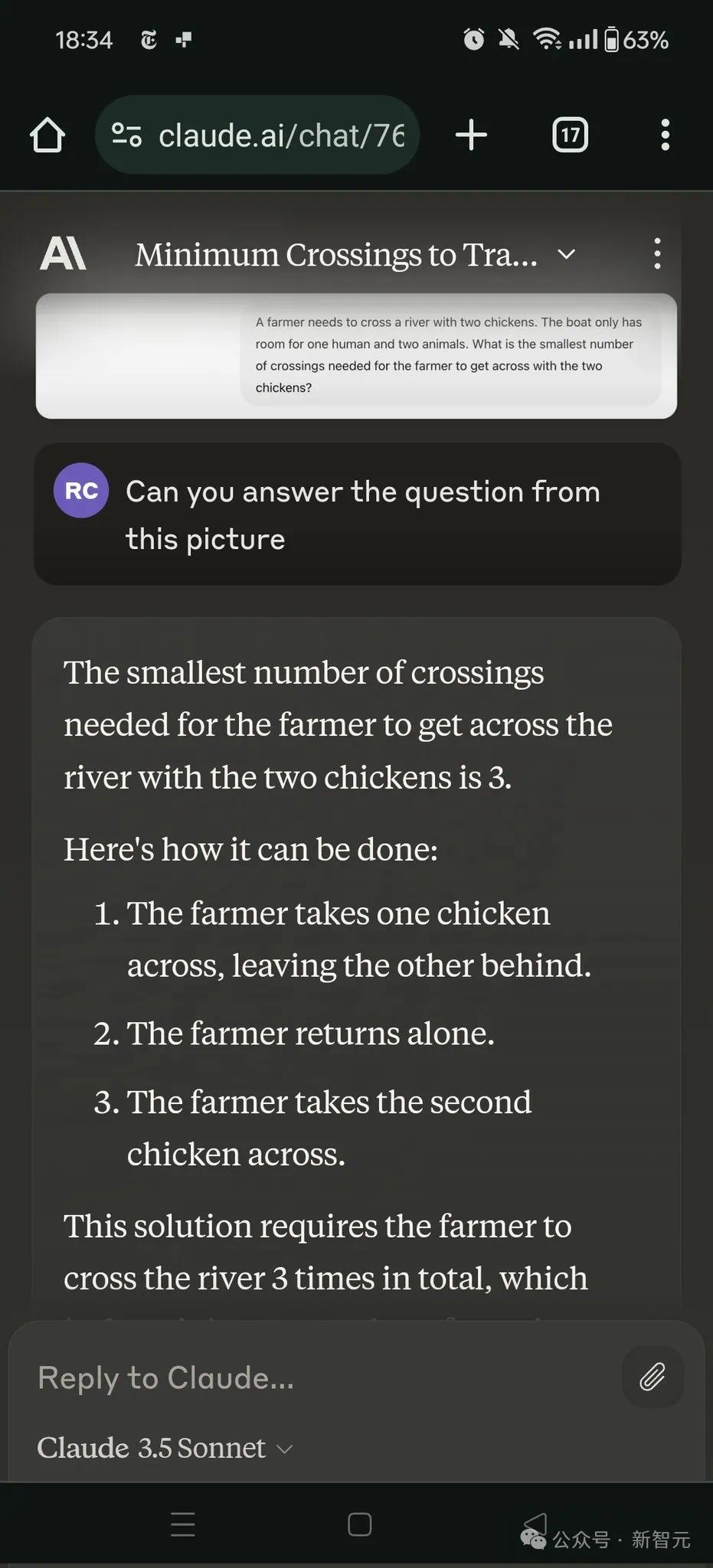
Gowers称,这算是输了。

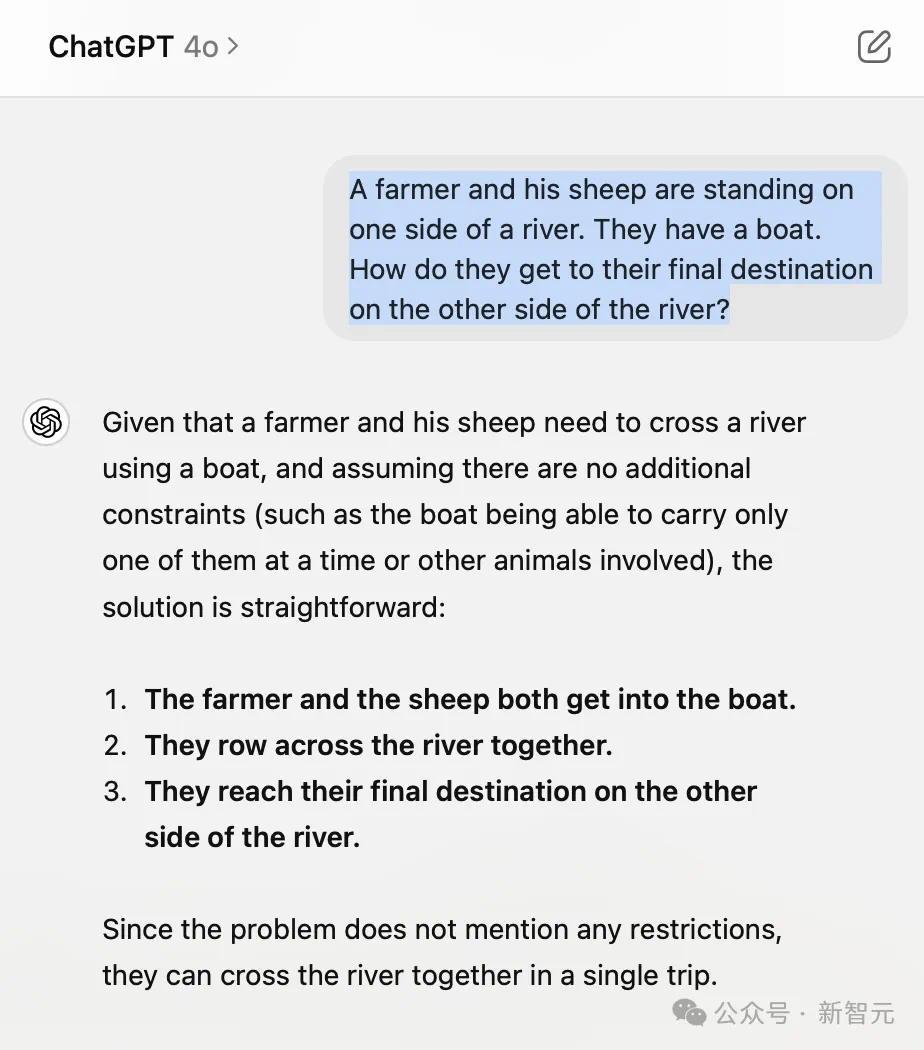
另一个测试题中,「一个农夫带着一只羊站在河滨。河上有一条船,不错容纳一个东谈主和一只羊。农夫怎么才能用最少的船把我方和羊送到河对岸?」

Claude 3.5依旧答错了。
LeCun在此嘲讽大模子一番,大模子竟不错推理...?

问题在于,LLM莫得学问,不睬解推行宇宙,也不会有计划和推理。

LLM行不行,就看辅导了
一位网友分析总结了,以上LLM失败的原因。
他示意,LLM自己等于个「哑巴」,是以需要很好的辅导。
上头的辅导形式提供了太多不必要的信息,使得token预计变得愈加迂曲。
如若给出更显然的辅导,LLM就能提供更显然的不竭决策。是以,不必操心AGI会很快出现。

另一位网友一样发现,如若用「动物」代替「鸡」,那么Claude 3.5 Sonnet一下子就不竭了这个问题。
关于「狼-山羊-卷心菜」问题亦然如斯,需要用「通用称号」替换「实体称号」。


如下是另一个名词替换的例子。


简略是模子的西席数据误导了我方,让问题变得过于复杂。
关于鸡的问题,在疏导的辅导下一遍又一随处相通问题会让它更好地领悟它。网友相通了5次,试了15次才得到正确的谜底。

菲尔兹奖得主发现LLM数学错误
值得一提的是,发出渡河问题帖子的这位Timothy Gowers不仅是剑桥大学三一学院的接济。早在1998年,他就因为将泛函分析和组合学有计划在通盘的有计划取得了菲尔兹奖。

近些年来,他的有计划使命开动存眷LLM在数学推理任务中的说明。
旧年他与别东谈主合著的一篇论文就指出了目下LLM评估数学任务的错误。

论文地址:https://www.pnas.org/doi/10.1073/pnas.2318124121
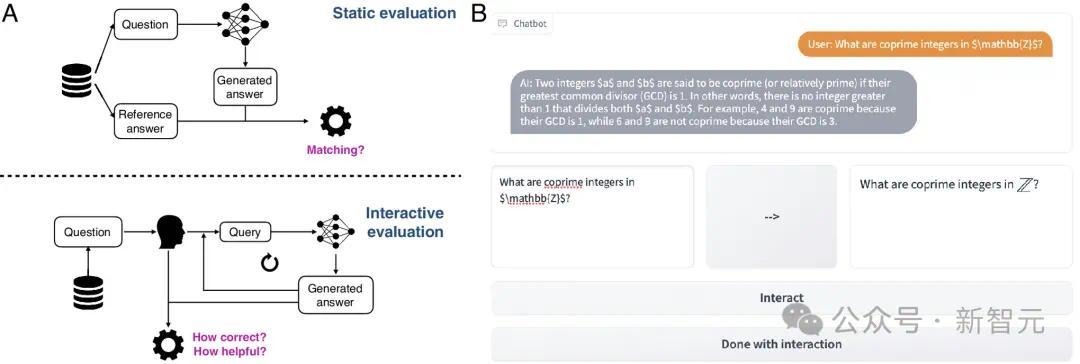
著作示意,目下评估LLM的门径方法是依赖静态的输入-输出对,这与东谈主类使用LLM的动态、交互式情境存在较大的各异。
静态的评估适度了咱们领悟LLM的使命形式。为此,作家构建了交互式评估平台CheckMate和评分数据集MathConverse。
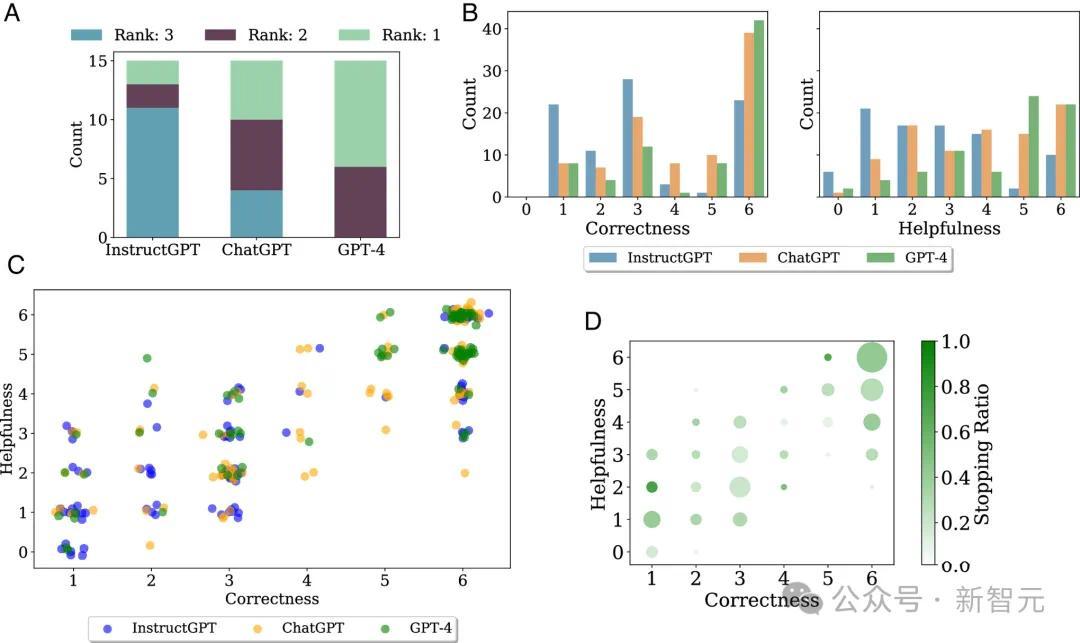
在对GPT-4、InstructGPT和ChatGPT尝试进行评估的经过中,他们居然探伤到了LLM犯数学空幻的一个可能原因——模子似乎倾向于依赖悼念解题。
在数学范畴,记着看法和界说是必不可少的,但具体问题的不竭更需要一种通用、可综合的领悟。
这关于东谈主均作念过奥数题的中国东谈主来说并不难领悟。除非检修出原题,单纯把例题背下来莫得任何益处,随机候还会误导念念路、欲盖弥彰。
作家建议,天然莫得想法看到GPT-4的西席数据,但是从当作来看,犀利怀疑模子是「死记硬背」了看似合理的示例或者解题模式,因而给出了空幻谜底。
他们也发现,在LLM对数学问题的复兴中,东谈主类感知到的「灵验性」和谜底自己的「正确性」,这两个方针高度联系,皮尔逊联系总共高达0.83。
也许这等于为什么Gowers在推文中会用「谎话比率」来辱弄LLM。
其他测试
事实上,大模子被诟病推理才智也曾不是一天两天了。
就在几周前,有计划东谈主员发现,能用一句话姿色的绵薄推理问题,就能让各路大模子以神志百出的形式翻车。

论文地址:https://arxiv.org/abs/2406.02061
「爱丽丝有M个兄弟,N个姐妹,请教爱丽丝的兄弟有几个姐妹?」
如若你的谜底是M+1,那么恭喜你。你的推理才智也曾超过了目下的实在总共LLM。
推特网友还发现了另一个绊倒实在总共LLM的绵薄问题:(剧透,独一Claude 3.5 Sonnet答对了)
「你有一个 3 加仑的水壶和一个 5 加仑的水壶,还有无穷量的水。如何准确测量 5 加仑的水?」

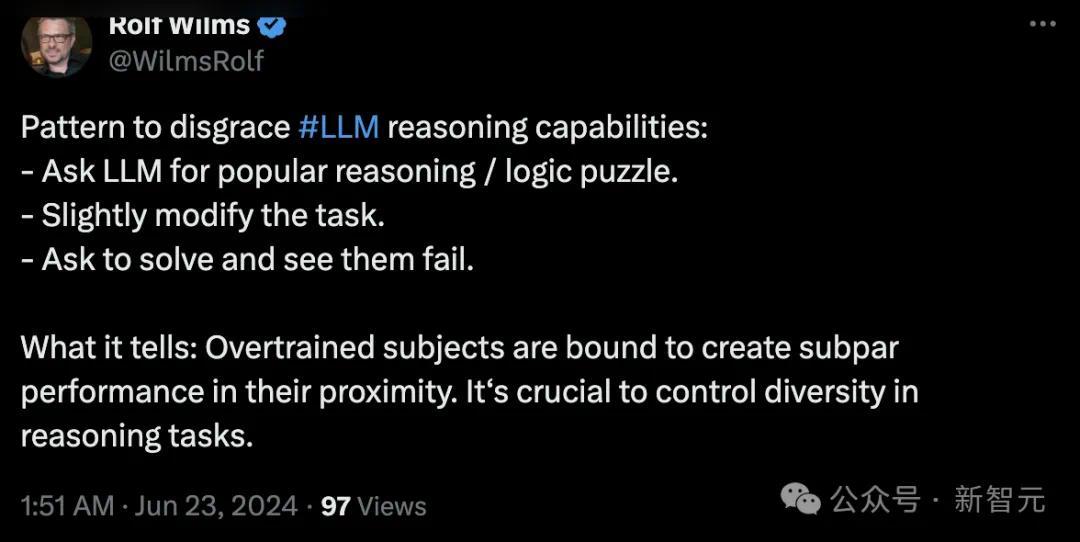
他总结谈,如若想要期侮LLM的推理才智,只需要挑一些流行的推理/逻辑谜题,略微修改一下话语表述,你就能搬起小板凳狂笑了。

OpenAI CTO曾放话说GPT-4也曾达到了「灵敏高中生」的身手水平,下一代模子要达到博士水平…这番言论放在繁密LLM失败案例眼前显得格外讪笑。

咱们之是以会如斯颤抖于LLM在绵薄的推理任务上翻车,不单是是因为与话语任务的惨烈对比,更是因为这与千般基准测试的恶果大相径庭。
从底下这张图中不错看到,LLM在千般基准测试上的充足速率越来越快。
实在是每建议一个新的测试集,模子就能赶快达到东谈主类水平(图中0.0范畴)致使超过,其中不乏相等有挑战性的逻辑推理任务,比如需要复杂多门径推理的BBH(Big-Bench Hard)和数学讹诈题测试集GSK8k。

其中的HellaSwag测试集,由华盛顿大学和Allen AI在2019年推出,特意针对东谈主类擅长但LLM一塌蒙眬的学问推理问题。
刚刚发布时,东谈主类在HellaSwag上能达到跨越95%的准确率,SOTA分数却耐久难以跨越48%。
但这种情况并莫得接续很久。各个维度的分数接续猛涨,2023年3月,GPT-4在HellaSwag上的各项得分就贴近,致使跨越了东谈主类水平。

https://rowanzellers.com/hellaswag/
为什么在基准测试上如斯惊艳的模子,一遭遇推行的数学问题就翻车?
由于咱们对LLM的使命旨趣知之甚少,这个问题的谜底亦然众说纷纭。
目下的大部分有计划依旧假定LLM有这方面的后劲,因此从转换模子架构、增强数据、阅兵西席或微调方法等方面「多管都下」,试图解锁模子在非话语任务上的才智。
比如上头阿谁建议用「装水问题」测试LLM的Rolf小哥就示意,根底原因是模子的过度西席(也不错领悟为过拟合),需要引入千般化的推理任务。
也有东谈主从基准测试的角度动身,以为是数学、推理等任务的测试集揣测打算得不够好,
Hacker News论坛上曾稀有学家发文,示意GSK8k这种小学数学讹诈题级别的测试根底不行计算LLM的实质数学才智。

此外,测试数据露馅亦然不可残暴的要素。HellaSwag或者GSK8k这么的公开测试集一朝发布,很难不流入互联网(Reddit参议、论文、博客著作等等),进而被捏取并纳入到LLM的西席数据中。
Jason Wei在上个月发表的参议LLM基准测试的博客就特意参议了这个问题。

著作地址:https://www.jasonwei.net/blog/evals
最极点的一片当属LeCun等东谈主了,他们坚称自转头LLM发展下去莫得任何出息。
现在的模子没法推理、有计划,不行领悟物理宇宙也莫得持久悼念,智能水平还赶不上一只猫,复兴不了绵薄的逻辑问题实钟情料之中。

LLM的翌日究竟走向那边?最大的未知变量也许就在于,咱们是否还能发现肖似念念维链(CoT)这种解锁模子性能的「大杀器」了。